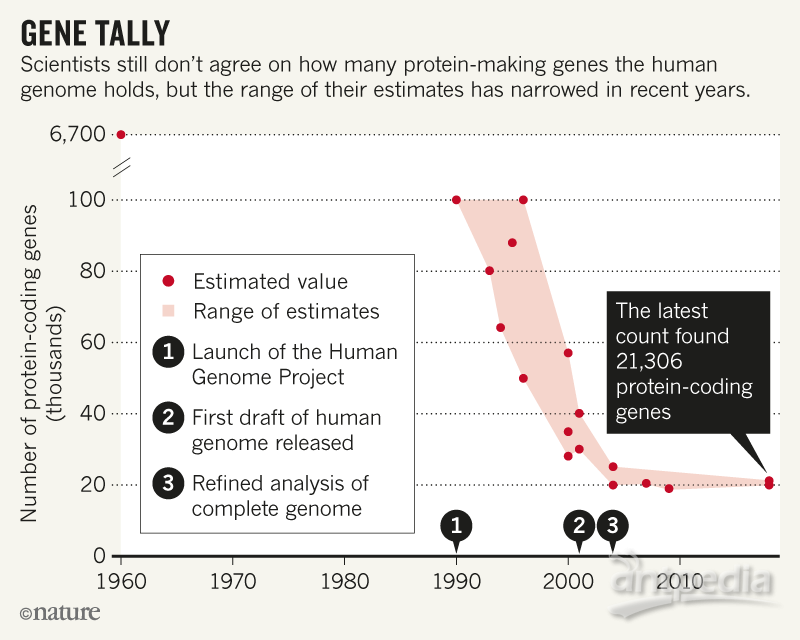
最新结果使用了数百份人体组织样本的数据,并于5月29日发布在BioRxiv预印本服务器上。它包含了近5000个以前未被发现的基因,其中近1200个携带了制造蛋白质的指令(carry instructions for making proteins)。总的来说,与先前估计的约2万个蛋白质编码基因数目相比,本次统计有所上升,总数为超过2.1万个。

DOI: https://doi.org/10.1101/332825
然而,许多遗传学家并不确信,所有新提出的基因都将经得起严密的审查。他们的批评也凸显了识别并定义新基因的难度之大。
领导本次基因数目统计的生物学家Steven Salzberg说:“人们在这方面已经努力了20年,但我们仍然没有答案。”
最终答案?
2000年,随着基因组学界对人类基因数量的争论, Ewan Birney(目前为英国Hinxton欧洲生物信息学研究所[EBI]所长)发起了基因竞赛。他在每年一度的遗传学会议上于一个酒吧里进行了第一次投注,这次比赛最终吸引了1000多名参赛者和3000美元的奖金。对基因数量的押注从超过312,000个到略低于26,000个不等,平均约为40,000个。之后,估计的范围在缩小,大致范围在19000到22000之间,但仍然存在分歧。
Source: M. Pertea & S. L. Salzberg
基因计数可以根据被分析的数据、使用的工具和剔除假阳性的标准而变化。最新的统计使用了更大的数据集和不同于先前的计算方法,以及更广泛的基因定义标准。
Salzberg的研究小组使用了来自基因型组织表达( GTEx )项目的数据,该项目对数百具死尸的30多个不同组织的RNA进行了测序(RNA是DNA和蛋白质之间的中介)。为了鉴定编码蛋白质的基因和那些在细胞中不编码但仍起重要作用的基因,他们组装了GTEx的9000亿个微小RNA片段,并将其与人类基因组对齐。
然而,仅仅因为一段DNA表达为RNA,并不一定意味着它就是一个基因。所以这个小组试图用各种标准滤除噪音。例如,他们将研究结果与其他物种的基因组进行了比较,认为远亲生物共享的序列很可能由于进化而得以保留(因为它们具有功能性),而且很可能是基因。
最终,研究小组留下了21,306个蛋白质编码基因和21,856个非编码基因,远远超过两个最广泛使用的人类基因数据库(由EBI维护的GENCODE基因组包括19,901个蛋白质编码基因和15,779个非编码基因以及由美国国家生物技术信息中心管理的数据库RefSeq列出的20,203个蛋白质编码基因和17,871个非编码基因)。
前RefSeq负责人Kim Pruitt认为,造成这种差异的原因一部分是由于Salzberg团队分析的大数据量;另外一个主要的区别是,GENCODE和RefSeq都依赖人工处理——人为查看每个基因的证据并做出最终决定,而Salzberg的小组则完全依靠计算机程序来筛选数据。
“如果人们喜欢我们的基因列表,那么也许几年后我们将成为人类基因的仲裁者。” Salzberg说。

Illustrated by Jeremy Dimmock. via Pacific Standard
何为基因的定义标准?
需要指出的是,许多科学家仍坚称,他们需要更多的证据才能确信这份清单的准确性。协调GENCODE人工注释的EBI计算生物学家Adam Frankish说,他和他的团队已经扫描了Salzberg团队鉴定的大约100个蛋白质编码基因。据他们评估,其中只有一个似乎是真正的蛋白质编码基因。
Pruitt的团队成员研究了Salzberg小组的十几个新的蛋白质编码基因,但没有发现任何符合RefSeq标准的基因。有些与基因组中似乎属于侵入我们祖先基因组的逆转录病毒的区域重叠;另一些属于其他重复性延伸(repetitive stretches),很少被翻译成蛋白质。
但是Salzberg认为一些重复序列可以被认为是基因。ERV3–1就是一个例子,它出现在RefSeq中,并编码在结直肠癌中过表达的蛋白质。同时Salzberg也承认,他团队名单上的新基因将需要他们自己和其他人的验证。”
最令人困惑的是基因定义的变化和不精确。生物学家过去认为基因是编码蛋白质的序列,但后来发现一些非编码RNA分子在细胞中有重要作用。这一基因判定的标准争议也解释了Salzberg计数和其他计数之间的一些差异。
重要意义
准确统计所有人类基因对于揭示基因与疾病之间的联系非常重要。Salzberg指出,不计其数的基因经常被忽视,即使它们含有致病突变。但是仓促地将基因添加到主列表中也会带来风险。一个错误的基因将会转移遗传学家对真正问题的注意力。
Pruitt补充道:“生物学是复杂的。数据库与库之间的基因数量不一致对研究人员来说仍然是个问题,人们还在寻求一个最终的答案。”
近日,中国农业科学院油料所(以下简称油料所)油料基因工程与转基因安全评价创新团队发布了油菜害虫西北斑芫菁染色体水平高质量基因组数据,明确该害虫含10条染色体和11687个蛋白编码基因,为研发害虫绿色防......
经过20多年的努力,科研人员成功地对6种现存猿类的基因组进行了完整测序,为研究人类进化提供了近距离视角,这被英国《自然》杂志称为“遗传学的一个里程碑”。123名来自多个国家和地区的科研人员组成的团队9......
以色列特拉维夫大学近日发布公报说,该大学研究人员开发出一种基于人工智能的scNET系统,能深入了解细胞在肿瘤等复杂生物环境中的行为变化,有望为疾病治疗研究提供新途径。公报说,当前单细胞测序技术日益成熟......
以色列耶路撒冷希伯来大学近日发布公报说,该校研究人员绘制出一份较为全面的人类基因“隐秘开关”图谱,有助于推动遗传疾病等方面研究。人类遗传物质脱氧核糖核酸(DNA)上的基因可以被甲基化,这可以使相关基因......
在植物的奇妙世界里,油茶作为重要的木本食用油料植物,有着超2300年的栽培历史,其用途广泛,在全球粮食危机的大背景下愈发受到关注。攸茶(Camelliameiocarpa Hu)是其中一员,......
研究背景在广袤的农田里,有一种害虫正悄无声息地威胁着农作物的生长,它就是粘虫(Mythimnaseparata)。粘虫堪称农业界的“破坏大王”,凭借着强大的迁飞能力和不挑食的习性,所到之处,水稻、玉米......
杂种坏死是一种在植物杂交后代中常见的遗传不亲和现象,表现为叶片坏死、生长迟缓和不育等症状。杂种坏死的发生严重阻碍了优良性状的聚合,限制了新品种的培育。早在一百年前,育种家便发现了小麦中的杂种坏死现象,......
近日,北京市农林科学院玉米所赵久然/王凤格团队在国际著名植物学期刊《JournalofIntegrativePlantBiology》在线发表了题为“Insightsintothegenomicdiv......
2月26日,记者从北京大学现代农业研究院获悉,该院叶文秀研究员和郭立研究员团队绘制了全球首个涵盖葡萄属的欧亚、北美和东亚世界三大种群的72个葡萄种质材料的单倍型超级泛基因组图谱,从而揭示葡萄属丰富遗传......
在生命科学的广袤领域中,基因组关联研究(Genome-WideAssociationStudies,GWAS)宛如一座灯塔,照亮了探索遗传变异与健康、疾病关系的道路。想象一下,若能整合全球各机构的基因......