实验概要
本实验分别对DNA片段、基因、启动子和外显子进行了甲基化的计算预测,并且随机选择了1000甲基化的和1000未甲基化的个体进行预测。用于甲基化预测的特征有:GC相关特征、四联体频率、转录因子结合位点(TFBSs)。所有预测方法均采用Weka提供的软件进行。
实验步骤
1. DNA甲基化数据
本研究基于在拟南芥中使用Tiling芯片第一次进行全基因组水平的DNA甲基化分析的实验结果。实验数据包括26,852个具有显著DNA甲基化水平的DNA片段,这些片段覆盖了22,554,840 bp并且代表了完全测序的拟南芥核基因组的~18.9%。拟南芥25,423表达基因中,作者将它们分为三部分:内部甲基化基因(33.3%),启动子甲基化基因(5.2%)和未甲基化基因(61.5%)。利用这些数据,我们确定了所有拟南芥基因的启动子和外显子的甲基化状态。我们分别对DNA片段、基因、启动子和外显子进行了甲基化的计算预测,并且随机选择了1,000甲基化的和1,000未甲基化的个体进行预测。
2. 用于甲基化预测的特征
1) GC相关特征
CpG岛的传统定义需要三个参数:序列一长度,GC含量和CpG ratio。我们利用Wilcoxon秩检验比较了甲基化和未甲基化的DNA片段的GC含量和CpG ratio值,并且发现这两个参数在甲基化和未甲基化的DNA片段间具有非常显著的差异。所以这两个参数被用作预测的两个特征。
在植物和动物中,甲基化主要在CG sequence context中发现。在进化过程中双核营酸TpG(以及它的反义互补CpA)的分布推测起来也和mCpGs的去甲基化有关。我们分别计数了甲基化和未甲基化片段中的双核普酸CpG和TpG,并且利用Wilcoxon秩检验比较它们在两类片段间的分布。显著差异意味着CpG和TpG的分布与DNA甲基化间的联系。我们采用了每1 kb中的CpG和TpG的数目作为预测的另外两个特征。
2) 四联体频率
人类淋巴细胞CpG岛甲基化的研究显示CpG岛甲基化与DNA序列中的四联体是高度相关的。所以我们直接从DNA序列计数每个四联体的频率,并且发现256个四联体中的153个在甲基化和未甲基化片段间具有显著差异。所以四联体频率被作为预测的特征。
3) 转录因子结合位点(TFBSs)
甲基可能破坏转录因子的结合位点并导致转录的失败,所以DNA甲基化能够抑制转录。这意味着在TFBSs和DNA甲基化间存在着联系。而且以前的研究己经显示在人类大脑中TFBSs与CpG岛的甲基化是相关的。所以我们预测某些TFBSs的分布可能在拟南芥的甲基化和未甲基化片段间存在差异。我们从PlantCARE,PLACE和AGRIS上得到了拟南芥的105个己知的TFBSs的Position weight matrices (PWM)。这些TFBSs被用于pattern searchprogram MotifScanner来扫描和确定推定的TFBSs的位置,采用默认的标准:最大启动子大小3kb并且没有启动子序列和上游基因有重叠。我们在拟南芥基因组中得到了%个TFBSs类。然后我们利用Wilcoxon rank-sum test比较了甲基化和未甲基化片段间的96个TFBSs的存在与否并且发现66个TFBSs具有显著差异。所以我们把TFBSs的存在与否作为甲基化预测的特征。
3. 预测方法
我们用了多种方法来测验预测性能,这些方法包括alternating decision tree (ADTree),Bayes network (BayesNet),C4.5 decision tree (C4.STree),simple decision table majority classifier (DecisionTable),logistic model trees (LMT),multinomial logistic regression model with a ridge estimator (Logistic),decision tree with naive Bayes classifiers at the Leaves (NBTree),rules from partial decision trees built using C4.5 decision tree (PART),forest of random trees (RandomForest),normalized Gaussian radial basisbasis function network (RBFNetwork),linear logistic regression models (SimpleLogstic),support vector machine (SVM) and voted perceptron algorithm (VotedPerceptron)。这里使用的所有预测方法都是Waikato environment for knowledge analysis (Weka)提供的,Weka是一个可以提供执行大量机器学习和统计算法的环境的Java软件包。所有这些方法的数据被准备成属性相关文件格式(ARFF),这种格式由所有个体和相应个体的属性值(逗号分隔)的列表构成。
4. 性能评估
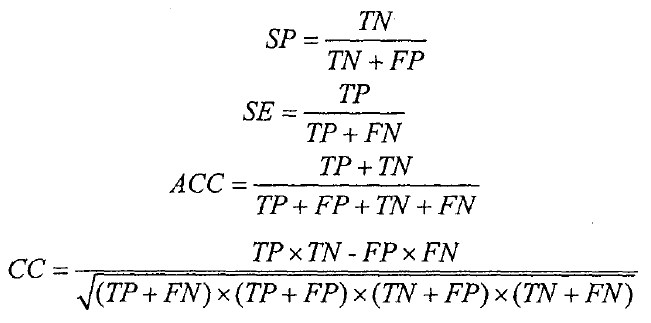
我们把所有的样本随机分成一个训练集(66%)和一个测试集。预测方法在训练集上进行训练然后在测试集上进行评估。我们使用特异性(SP),敏感性((SE)、精确性(ACC)和相关系数((CC)来评估预测方法的性能。将未甲基化的样本作为阳性类别,甲基化的样本作为阴性类别,我们使用下面的公式计算SP,SE,ACC和CC:

TP,TN,FP和FN分别代表真阳性、真阴性、假阳性和假阴性。这些参数比只使用正确预测的总百分率能够提供一个对分类性能的更精确的评估。
附 件 (共1个附件,占34KB)
1.jpg
34KB
查看
在近日一项发表于《自然》的研究中,科学家绘制出迄今最详尽的人类活细胞内DNA折叠、环状缠绕和移动的图谱,展示了基因组结构随时间推移的变化情况,揭示了隐藏的基因调控机制,是了解DNA结构如何塑造人类生物......
图基于卷对卷流体的新一代快速低成本基因测序技术在国家自然科学基金项目(批准号:22027805、22334004、22421002)等资助下,福州大学杨黄浩、陈秋水团队与华大生命科学研究院秦彦哲、章文......
荷兰乌得勒支大学研究人员开发出一款全新荧光传感器,可在活细胞乃至活体生物中实时监测DNA损伤及修复过程,为癌症研究、药物安全测试和衰老生物学等领域提供了重要的新工具。相关成果发表于新一期《自然·通讯》......
三维基因组互作与表观遗传修饰是基因表达调控的重要因素,其动态变化与细胞生长发育及癌症等疾病的发生发展密切相关。解析染色质在活细胞内的时空动态,是理解基因调控机制的重要科学问题。现有基于CRISPR-C......
1812年,法国皇帝拿破仑一世从俄罗斯莫斯科撤退时,其大部分军队因饥饿、疾病和寒冷的冬天而损失殆尽。如今,对这撤退途中丧生的30万士兵的部分遗骸的DNA的分析发现,两种未曾预料到的细菌性疾病很可能增加......
1812年夏,法兰西皇帝拿破仑·波拿巴率50万大军入侵俄罗斯帝国。然而到12月时,这支军队仅余零星残部。历史记载将此次“全军覆没”归因于饥寒交迫与斑疹伤寒。但一项新研究表示,从士兵牙齿中提取的DNA,......
美国北卡罗来纳大学研究团队研发出一种名为“DNA花朵”的微型机器人。这种机器人具有独特的自适应环境变化能力,能够像生物体一样,根据周围环境改变形状和行为。“DNA花朵”机器人由DNA与无机材料结合形成......
瑞士苏黎世联邦理工学院科学家在最新一期《自然》杂志上发表论文称,他们开发出一款名为MetaGraph的DNA搜索引擎,能快速、高效地检索公共生物学数据库中的海量信息,为研究生命科学提供了强大的专业工具......
究竟是什么让人脑与众不同?美国加州大学圣迭戈分校研究团队发现了一个名为HAR123的小型DNA片段,这将是解开人类大脑独特性之谜的关键。相关研究成果发表于新一期《科学进展》杂志。最新研究表明,HAR1......
近日,中国农业科学院深圳农业基因组研究所(岭南现代农业科学与技术广东省实验室深圳分中心)和佛山鲲鹏现代农业研究院研究员唐中林团队在国际期刊《肠道微生物》(GutMicrobes)上发表论文。该研究揭示......